Publications
Recent publications and preprints in reverse chronological order. For the latest updates, see my Google Scholar profile.
2025
-
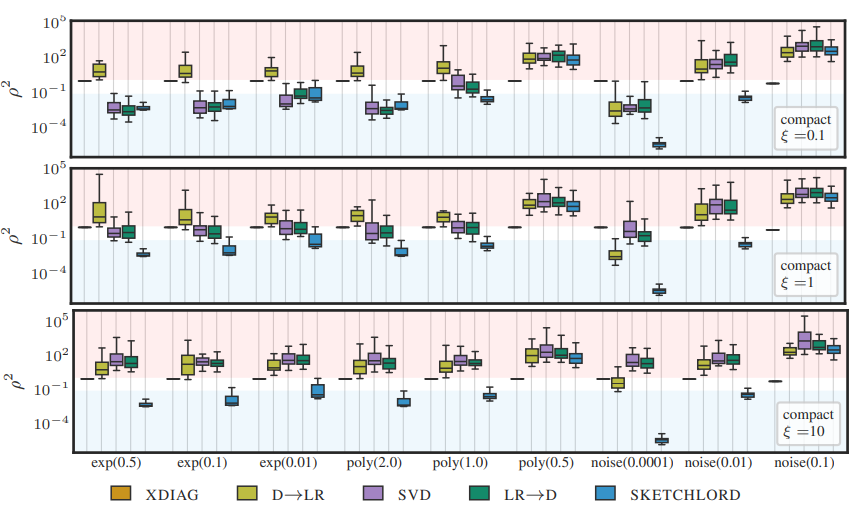 Sketching Low-Rank Plus Diagonal MatricesAndres Fernandez, Felix Dangel, Philipp Hennig, and 1 more author2025We propose a sketched method to estimate low-rank plus diagonal linear operators.
Sketching Low-Rank Plus Diagonal MatricesAndres Fernandez, Felix Dangel, Philipp Hennig, and 1 more author2025We propose a sketched method to estimate low-rank plus diagonal linear operators.Many relevant machine learning and scientific computing tasks involve high-dimensional linear operators accessible only via costly matrix-vector products. In this context, recent advances in sketched methods have enabled the construction of *either* low-rank *or* diagonal approximations from few matrix-vector products. This provides great speedup and scalability, but approximation errors arise due to the assumed simpler structure. This work introduces SKETCHLORD, a method that simultaneously estimates both low-rank *and* diagonal components, targeting the broader class of Low-Rank *plus* Diagonal (LoRD) linear operators. We demonstrate theoretically and empirically that this joint estimation is superior also to any sequential variant (diagonal-then-low-rank or low-rank-then-diagonal). Then, we cast SKETCHLORD as a convex optimization problem, leading to a scalable algorithm. Comprehensive experiments on synthetic (approximate) LoRD matrices confirm SKETCHLORD’s performance in accurately recovering these structures. This positions it as a valuable addition to the structured approximation toolkit, particularly when high-fidelity approximations are desired for large-scale operators, such as the deep learning Hessian.
@misc{Fernandez2025Sketchlord, title = {Sketching Low-Rank Plus Diagonal Matrices}, author = {Fernandez, Andres and Dangel, Felix and Hennig, Philipp and Schneider, Frank}, year = {2025}, eprint = {2509.23587}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2509.23587}, note = {}, } - Accelerating Non-Conjugate Gaussian Processes By Trading Off Computation For UncertaintyLukas Tatzel, Jonathan Wenger, Frank Schneider, and 1 more authorTransactions on Machine Learning Research, 2025We introduce iterNCGP, a family of efficient inference algorithms for NCGPs with a tunable trade-off between computational savings and added uncertainty.
Non-conjugate Gaussian processes (NCGPs) define a flexible probabilistic framework to model categorical, ordinal and continuous data, and are widely used in practice. However, exact inference in NCGPs is prohibitively expensive for large datasets, thus requiring approximations in practice. The approximation error adversely impacts the reliability of the model and is not accounted for in the uncertainty of the prediction. We introduce a family of iterative methods that explicitly model this error. They are uniquely suited to parallel modern computing hardware, efficiently recycle computations, and compress information to reduce both the time and memory requirements for NCGPs. As we demonstrate on large-scale classification problems, our method significantly accelerates posterior inference compared to competitive baselines by trading off reduced computation for increased uncertainty.
@article{Tatzel2025Accelerating, title = {Accelerating Non-Conjugate Gaussian Processes By Trading Off Computation For Uncertainty}, author = {Tatzel, Lukas and Wenger, Jonathan and Schneider, Frank and Hennig, Philipp}, journal = {Transactions on Machine Learning Research}, issn = {2835-8856}, year = {2025}, url = {https://openreview.net/forum?id=UdcF3JbSKb}, note = {}, } - Connecting Parameter Magnitudes and Hessian Eigenspaces at Scale using Sketched MethodsAndres Fernandez, Frank Schneider, Maren Mahsereci, and 1 more authorTransactions on Machine Learning Research (TMLR), 2025We observe that the top Hessian eigenvectors overlaps with the space of large magnitude parameters.
Recently, it has been observed that when training a deep neural net with SGD, the majority of the loss landscape’s curvature quickly concentrates in a tiny top eigenspace of the loss Hessian, which remains largely stable thereafter. Independently, it has been shown that successful magnitude pruning masks for deep neural nets emerge early in training and remain stable thereafter. In this work, we study these two phenomena jointly and show that they are connected: We develop a methodology to measure the similarity between arbitrary parameter masks and Hessian eigenspaces via Grassmannian metrics. We identify overlap as the most useful such metric due to its interpretability and stability. To compute overlap, we develop a matrix-free algorithm based on sketched SVDs that allows us to compute over 1000 Hessian eigenpairs for nets with over 10M parameters—an unprecedented scale by several orders of magnitude. Our experiments reveal an overlap between magnitude parameter masks and top Hessian eigenspaces consistently higher than chance-level, and that this effect gets accentuated for larger network sizes. This result indicates that top Hessian eigenvectors tend to be concentrated around larger parameters, or equivalently, that larger parameters tend to align with directions of larger loss curvature. Our work provides a methodology to approximate and analyze deep learning Hessians at scale, as well as a novel insight on the structure of their eigenspace.
@article{fernandez2025connecting, title = {Connecting Parameter Magnitudes and Hessian Eigenspaces at Scale using Sketched Methods}, author = {Fernandez, Andres and Schneider, Frank and Mahsereci, Maren and Hennig, Philipp}, journal = {Transactions on Machine Learning Research (TMLR)}, issn = {2835-8856}, year = {2025}, url = {https://openreview.net/forum?id=yGGoOVpBVP}, note = {}, } -
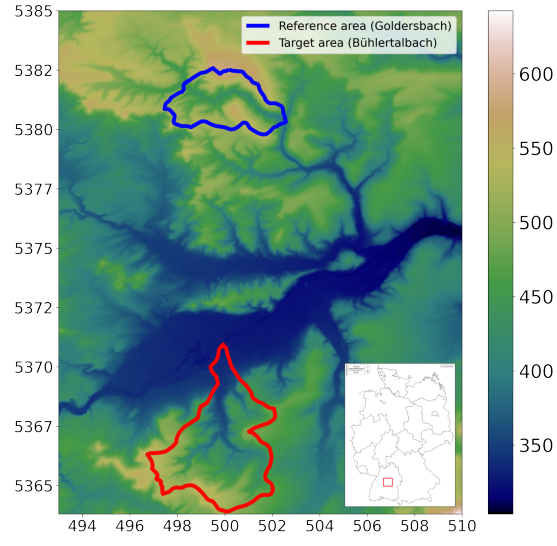 Quantifying spatial uncertainty to improve soil predictions in data-sparse regionsKerstin Rau, Katharina Eggensperger, Frank Schneider, and 3 more authorsSOIL, 2025We use a last-layer Laplace approximation to measure uncertainty in data-sprase regions for neural network soil predictions
Quantifying spatial uncertainty to improve soil predictions in data-sparse regionsKerstin Rau, Katharina Eggensperger, Frank Schneider, and 3 more authorsSOIL, 2025We use a last-layer Laplace approximation to measure uncertainty in data-sprase regions for neural network soil predictionsArtificial Neural Networks (ANNs) are valuable tools for predicting soil properties using large datasets. However, a common challenge in soil sciences is the uneven distribution of soil samples, which often results from past sampling projects that heavily sample certain areas while leaving similar yet geographically distant regions under-sampled. One potential solution to this problem is to transfer an already trained model to other similar regions. Robust spatial uncertainty quantification is crucial for this purpose, yet often overlooked in current research. We address this issue by using a Bayesian deep learning technique, Laplace Approximations, to quantify spatial uncertainty. This produces a probability measure encoding where the model’s prediction is deemed reliable, and where a lack of data should lead to a high uncertainty. We train such an ANN on a soil landscape dataset from a specific region in southern Germany and then transfer the trained model to another unseen but to some extend similar region, without any further model training. The model effectively generalized alluvial patterns, demonstrating its ability to recognize repetitive features of river systems. However, the model showed a tendency to favor overrepresented soil units, underscoring the importance of balancing training datasets to reduce overconfidence in dominant classes. Quantifying uncertainty in this way allows stakeholders to better identify regions and settings in need of further data collection, enhancing decision-making and prioritizing efforts in data collection. Our approach is computationally lightweight and can be added post-hoc to existing deep learning solutions for soil prediction, thus offering a practical tool to improve soil property predictions in under-sampled areas, as well as optimizing future sampling strategies, ensuring resources are allocated efficiently for maximum data coverage and accuracy.
@article{Rau2024Quantifying, title = {Quantifying spatial uncertainty to improve soil predictions in data-sparse regions}, journal = {SOIL}, volume = {11}, pages = {833--847}, year = {2025}, number = {2}, url = {https://soil.copernicus.org/articles/11/833/2025/}, doi = {10.5194/soil-11-833-2025}, author = {Rau, Kerstin and Eggensperger, Katharina and Schneider, Frank and Blaschek, Michael and Hennig, Philipp and Scholten, Thomas}, } - Accelerating neural network training: An analysis of the AlgoPerf competitionPriya Kasimbeg*, Frank Schneider*, Runa Eschenhagen, and 11 more authorsIn International Conference on Learning Representations (ICLR), 2025We analyze the results of the inaugural AlgoPerf competition
The goal of the AlgoPerf: Training Algorithms competition is to evaluate practical speed-ups in neural network training achieved solely by improving the underlying training algorithms. In the external tuning ruleset, submissions must provide workload-agnostic hyperparameter search spaces, while in the self-tuning ruleset they must be completely hyperparameter-free. In both rulesets, submissions are compared on time-to-result across multiple deep learning workloads, training on fixed hardware. This paper presents the inaugural AlgoPerf competition’s results, which drew 18 diverse submissions from 10 teams. Our investigation reveals several key findings: (1) The winning submission in the external tuning ruleset, using Distributed Shampoo, demonstrates the effectiveness of non-diagonal preconditioning over popular methods like Adam, even when compared on wall-clock runtime. (2) The winning submission in the self-tuning ruleset, based on the Schedule Free AdamW algorithm, demonstrates a new level of effectiveness for completely hyperparameter-free training algorithms. (3) The top-scoring submissions were surprisingly robust to workload changes. We also discuss the engineering challenges encountered in ensuring a fair comparison between different training algorithms. These results highlight both the significant progress so far, and the considerable room for further improvements.
@inproceedings{Kasimbeg2025AlgoPerfResults, title = {Accelerating neural network training: An analysis of the {AlgoPerf} competition}, author = {Kasimbeg, Priya and Schneider, Frank and Eschenhagen, Runa and Bae, Juhan and Sastry, Chandramouli Shama and Saroufim, Mark and Boyuan, Feng and Wright, Less and Yang, Edward Z. and Nado, Zachary and Medapati, Sourabh and Hennig, Philipp and Rabbat, Michael and Dahl, George E.}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2025}, url = {https://openreview.net/forum?id=CtM5xjRSfm}, }





2024
-
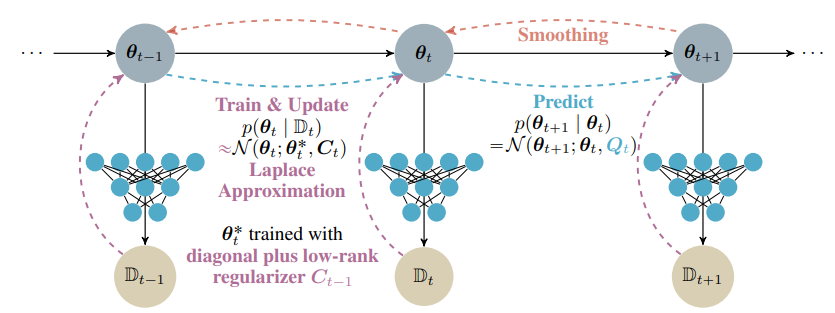 Efficient Weight-Space Laplace-Gaussian Filtering and Smoothing for Sequential Deep LearningJoanna Sliwa, Frank Schneider, Nathanael Bosch, and 2 more authors2024We propose a Laplace-Gaussian filtering and smoothing framework for sequential deep learning
Efficient Weight-Space Laplace-Gaussian Filtering and Smoothing for Sequential Deep LearningJoanna Sliwa, Frank Schneider, Nathanael Bosch, and 2 more authors2024We propose a Laplace-Gaussian filtering and smoothing framework for sequential deep learningEfficiently learning a sequence of related tasks, such as in continual learning, poses a significant challenge for neural nets due to the delicate trade-off between catastrophic forgetting and loss of plasticity. We address this challenge with a grounded framework for sequentially learning related tasks based on Bayesian inference. Specifically, we treat the model’s parameters as a nonlinear Gaussian state-space model and perform efficient inference using Gaussian filtering and smoothing. This general formalism subsumes existing continual learning approaches, while also offering a clearer conceptual understanding of its components. Leveraging Laplace approximations during filtering, we construct Gaussian posterior measures on the weight space of a neural network for each task. We use it as an efficient regularizer by exploiting the structure of the generalized Gauss-Newton matrix (GGN) to construct diagonal plus low-rank approximations. The dynamics model allows targeted control of the learning process and the incorporation of domain-specific knowledge, such as modeling the type of shift between tasks. Additionally, using Bayesian approximate smoothing can enhance the performance of task-specific models without needing to re-access any data.
@misc{Sliwa2024LR-LGF, title = {Efficient Weight-Space Laplace-Gaussian Filtering and Smoothing for Sequential Deep Learning}, author = {Sliwa, Joanna and Schneider, Frank and Bosch, Nathanael and Kristiadi, Agustinus and Hennig, Philipp}, year = {2024}, eprint = {2410.06800}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2410.06800}, } -
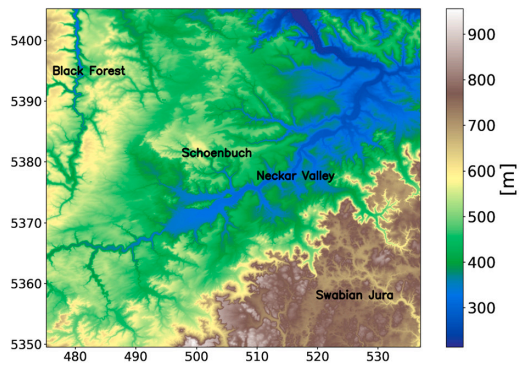 How can we quantify, explain, and apply the uncertainty of complex soil maps predicted with neural networks?Kerstin Rau, Katharina Eggensperger, Frank Schneider, and 2 more authorsScience of The Total Environment, 2024We use a last-layer Laplace approximation to quantify uncertainty in soil maps predicted with neural networks
How can we quantify, explain, and apply the uncertainty of complex soil maps predicted with neural networks?Kerstin Rau, Katharina Eggensperger, Frank Schneider, and 2 more authorsScience of The Total Environment, 2024We use a last-layer Laplace approximation to quantify uncertainty in soil maps predicted with neural networksArtificial neural networks (ANNs) have proven to be a useful tool for complex questions that involve large amounts of data. Our use case of predicting soil maps with ANNs is in high demand by government agencies, construction companies, or farmers, given cost and time intensive field work. However, there are two main challenges when applying ANNs. In their most common form, deep learning algorithms do not provide interpretable predictive uncertainty. This means that properties of an ANN such as the certainty and plausibility of the predicted variables, rely on the interpretation by experts rather than being quantified by evaluation metrics validating the ANNs. Further, these algorithms have shown a high confidence in their predictions in areas geographically distant from the training area or areas sparsely covered by training data. To tackle these challenges, we use the Bayesian deep learning approach ’last-layer Laplace approximation’, which is specifically designed to quantify uncertainty into deep networks, in our explorative study on soil classification. It corrects the overconfident areas without reducing the accuracy of the predictions, giving us a more realistic uncertainty expression of the model’s prediction. In our study area in southern Germany, we subdivide the soils into soil regions and as a test case we explicitly exclude two soil regions in the training area but include these regions in the prediction. Our results emphasize the need for uncertainty measurement to obtain more reliable and interpretable results of ANNs, especially for regions far away from the training area. Moreover, the knowledge gained from this research addresses the problem of overconfidence of ANNs and provides valuable information on the predictability of soil types and the identification of knowledge gaps. By analyzing regions where the model has limited data support and, consequently, high uncertainty, stakeholders can recognize the areas that require more data collection efforts.
@article{Rau2024Soil, title = {How can we quantify, explain, and apply the uncertainty of complex soil maps predicted with neural networks?}, journal = {Science of The Total Environment}, volume = {944}, pages = {173720}, year = {2024}, issn = {0048-9697}, doi = {https://doi.org/10.1016/j.scitotenv.2024.173720}, url = {https://www.sciencedirect.com/science/article/pii/S0048969724038671}, author = {Rau, Kerstin and Eggensperger, Katharina and Schneider, Frank and Hennig, Philipp and Scholten, Thomas}, keywords = {Spatial prediction, Model uncertainty, Digital soil mapping, Soil type, Last-layer Laplace approximation}, }


2023
- Kronecker-Factored Approximate Curvature for Modern Neural Network ArchitecturesRuna Eschenhagen, Alexander Immer, Richard Turner, and 2 more authorsIn Neural Information Processing Systems (NeurIPS), 2023We extend Kronecker-Factored Approximate Curvature to generic modern neural network architectures
The core components of many modern neural network architectures, such as transformers, convolutional, or graph neural networks, can be expressed as linear layers with weight-sharing. Kronecker-Factored Approximate Curvature (K-FAC), a second-order optimisation method, has shown promise to speed up neural network training and thereby reduce computational costs. However, there is currently no framework to apply it to generic architectures, specifically ones with linear weight-sharing layers. In this work, we identify two different settings of linear weight-sharing layers which motivate two flavours of K-FAC expand and reduce. We show that they are exact for deep linear networks with weight-sharing in their respective setting. Notably, K-FAC-reduce is generally faster than K-FAC-expand, which we leverage to speed up automatic hyperparameter selection via optimising the marginal likelihood for a Wide ResNet. Finally, we observe little difference between these two K-FAC variations when using them to train both a graph neural network and a vision transformer. However, both variations are able to reach a fixed validation metric target in 50-75% of the number of steps of a first-order reference run, which translates into a comparable improvement in wall-clock time. This highlights the potential of applying K-FAC to modern neural network architectures.
@inproceedings{Eschenhagen2023KFAC, author = {Eschenhagen, Runa and Immer, Alexander and Turner, Richard and Schneider, Frank and Hennig, Philipp}, booktitle = {Neural Information Processing Systems (NeurIPS)}, title = {{Kronecker-Factored Approximate Curvature for Modern Neural Network Architectures}}, url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/6a6679e3d5b9f7d5f09cdb79a5fc3fd8-Paper-Conference.pdf}, year = {2023}, } -
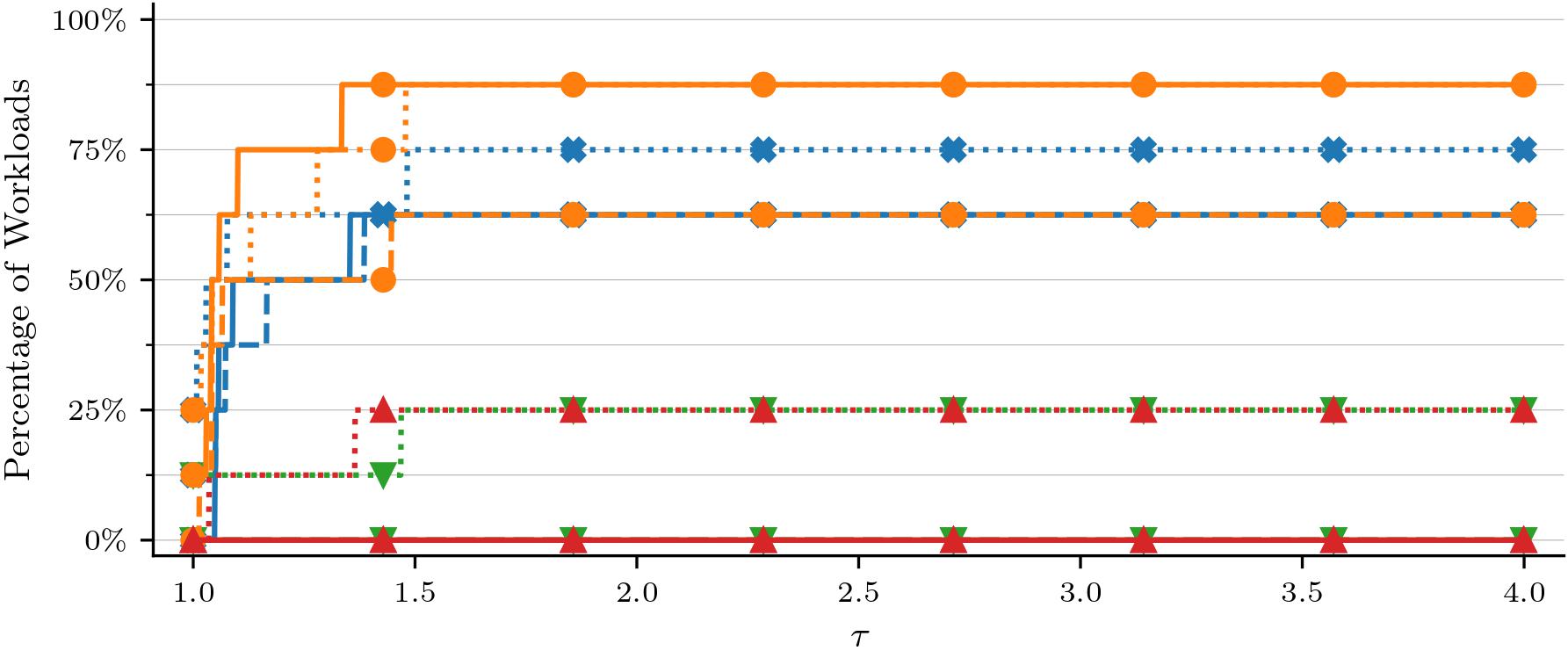 Benchmarking Neural Network Training AlgorithmsGeorge E. Dahl, Frank Schneider, Zachary Nado, and 22 more authors2023We motivate, present, and justify our new AlgoPerf Training Algorithms benchmark
Benchmarking Neural Network Training AlgorithmsGeorge E. Dahl, Frank Schneider, Zachary Nado, and 22 more authors2023We motivate, present, and justify our new AlgoPerf Training Algorithms benchmarkTraining algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
@misc{Dahl2023AlgoPerf, author = {Dahl, George E. and Schneider, Frank and Nado, Zachary and Agarwal, Naman and Sastry, Chandramouli Shama and Hennig, Philipp and Medapati, Sourabh and Eschenhagen, Runa and Kasimbeg, Priya and Suo, Daniel and Bae, Juhan and Gilmer, Justin and Peirson, Abel L. and Khan, Bilal and Anil, Rohan and Rabbat, Mike and Krishnan, Shankar and Snider, Daniel and Amid, Ehsan and Chen, Kongtao and Maddison, Chris J. and Vasudev, Rakshith and Badura, Michal and Garg, Ankush and Mattson, Peter}, title = {{Benchmarking Neural Network Training Algorithms}}, year = {2023}, archiveprefix = {arXiv}, eprint = {2306.07179}, }


2022
-
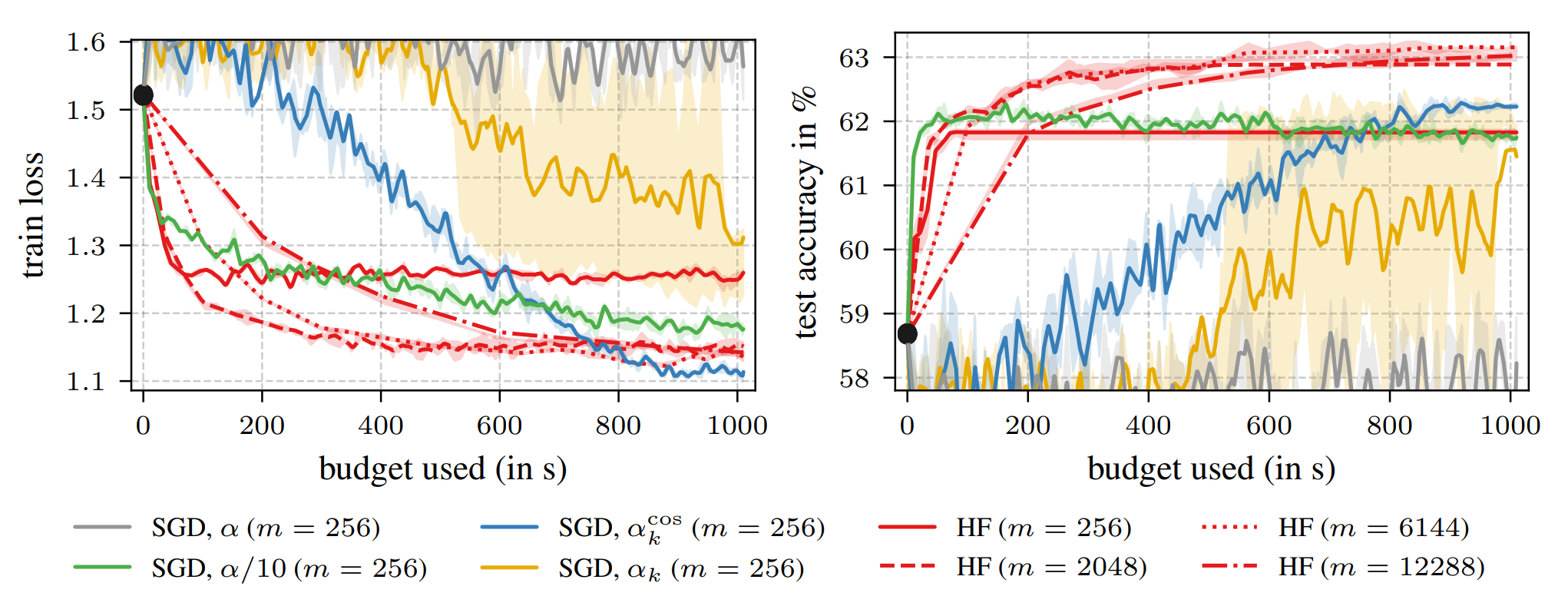 Late-Phase Second-Order TrainingLukas Tatzel, Philipp Hennig, and Frank SchneiderIn Has it Trained Yet? NeurIPS 2022 Workshop, 2022We show that performing a few costly but precise second-order steps can outperform first-order alternatives in wall-clock runtime
Late-Phase Second-Order TrainingLukas Tatzel, Philipp Hennig, and Frank SchneiderIn Has it Trained Yet? NeurIPS 2022 Workshop, 2022We show that performing a few costly but precise second-order steps can outperform first-order alternatives in wall-clock runtimeTowards the end of training, stochastic first-order methods such as SGD and Adam go into diffusion and no longer make significant progress. In contrast, Newton-type methods are highly efficient close to the optimum, in the deterministic case. Therefore, these methods might turn out to be a particularly efficient tool for the final phase of training in the stochastic deep learning context as well. In our work, we study this idea by conducting an empirical comparison of a second-order Hessian-free optimizer and different first-order strategies with learning rate decays for late-phase training. We show that performing a few costly but precise second-order steps can outperform first-order alternatives in wall-clock runtime.
@inproceedings{Tatzel2022LatePhase, title = {{Late-Phase Second-Order Training}}, author = {Tatzel, Lukas and Hennig, Philipp and Schneider, Frank}, booktitle = {{Has it Trained Yet? NeurIPS 2022 Workshop}}, year = {2022}, } -
 Understanding Deep Learning Optimization via Benchmarking and DebuggingFrank SchneiderUniversity of Tübingen, 2022Ph.D. Thesis
Understanding Deep Learning Optimization via Benchmarking and DebuggingFrank SchneiderUniversity of Tübingen, 2022Ph.D. ThesisThe central paradigm of machine learning (ML) is the idea that computers can learn the strategies needed to solve a task without being explicitly programmed to do so. The hope is that given data, computers can recognize underlying patterns and figure out how to perform tasks without extensive human oversight. To achieve this, many machine learning problems are framed as minimizing a loss function, which makes optimization methods a core part of training ML models. Machine learning and in particular deep learning is often perceived as a cutting-edge technology, the underlying optimization algorithms, however, tend to resemble rather simplistic, even archaic methods. Crucially, they rely on extensive human intervention to successfully train modern neural networks. One reason for this tedious, finicky, and lengthy training process lies in our insufficient understanding of optimization methods in the challenging deep learning setting. As a result, training neural nets, to this day, has the reputation of being more of an art form than a science and requires a level of human assistance that runs counter to the core principle of ML. Although hundreds of optimization algorithms for deep learning have been proposed, there is no widely agreed-upon protocol for evaluating their performance. Without a standardized and independent evaluation protocol, it is difficult to reliably demonstrate the usefulness of novel methods. In this thesis, we present strategies for quantitatively and reproducibly comparing deep learning optimizers in a meaningful way. This protocol considers the unique challenges of deep learning such as the inherent stochasticity or the crucial distinction between learning and pure optimization. It is formalized and automatized in the Python package DeepOBS and allows fairer, faster, and more convincing empirical comparisons of deep learning optimizers. Based on this benchmarking protocol, we compare fifteen popular deep learning optimizers to gain insight into the field’s current state. To provide evidence-backed heuristics for choosing among the growing list of optimization methods, we extensively evaluate them with roughly 50,000 training runs. Our benchmark indicates that the comparably traditional Adam optimizer remains a strong but not dominating contender and that newer methods fail to consistently outperform it. In addition to the optimizer, other causes can impede neural network training, such as inefficient model architectures or hyperparameters. Traditional performance metrics, such as training loss or validation accuracy, can show if a model is learning or not, but not why. To provide this understanding and a glimpse into the black box of neural networks, we developed Cockpit, a debugging tool specifically for deep learning. It combines novel and proven observables into a live monitoring tool for practitioners. Among other findings, Cockpit reveals that well-tuned training runs consistently overshoot the local minimum, at least for significant portions of the training. The use of thorough benchmarking experiments and tailored debugging tools improves our understanding of neural network training. In the absence of theoretical insights, these empirical results and practical tools are essential for guiding practitioners. More importantly, our results show that there is a need and a clear path for fundamentally different optimization methods to make deep learning more accessible, robust, and resource-efficient.
@phdthesis{Schneider2022PhD, author = {Schneider, Frank}, title = {{Understanding Deep Learning Optimization via Benchmarking and Debugging}}, school = {University of Tübingen}, year = {2022}, note = {Ph.D. Thesis} }


2021
- Cockpit: A Practical Debugging Tool for the Training of Deep Neural NetworksFrank Schneider*, Felix Dangel*, and Philipp HennigIn Neural Information Processing Systems (NeurIPS), 2021We introduce a visual and statistical debugger specifically designed for deep learning helping to understand the dynamics of neural network training
When engineers train deep learning models, they are very much ’flying blind’. Commonly used methods for real-time training diagnostics, such as monitoring the train/test loss, are limited. Assessing a network’s training process solely through these performance indicators is akin to debugging software without access to internal states through a debugger. To address this, we present Cockpit, a collection of instruments that enable a closer look into the inner workings of a learning machine, and a more informative and meaningful status report for practitioners. It facilitates the identification of learning phases and failure modes, like ill-chosen hyperparameters. These instruments leverage novel higher-order information about the gradient distribution and curvature, which has only recently become efficiently accessible. We believe that such a debugging tool, which we open-source for PyTorch, is a valuable help in troubleshooting the training process. By revealing new insights, it also more generally contributes to explainability and interpretability of deep nets.
@inproceedings{Schneider2021Cockpit, author = {Schneider, Frank and Dangel, Felix and Hennig, Philipp}, booktitle = {Neural Information Processing Systems (NeurIPS)}, editor = {Ranzato, M. and Beygelzimer, A. and Dauphin, Y. and Liang, P.S. and Vaughan, J. Wortman}, pages = {20825--20837}, publisher = {Curran Associates, Inc.}, title = {Cockpit: A Practical Debugging Tool for the Training of Deep Neural Networks}, url = {https://proceedings.neurips.cc/paper_files/paper/2021/file/ae3539867aaeec609a4260c6feb725f4-Paper.pdf}, volume = {34}, year = {2021}, } - Descending through a Crowded Valley - Benchmarking Deep Learning OptimizersRobin M. Schmidt*, Frank Schneider*, and Philipp HennigIn International Conference on Machine Learning (ICML), 2021We empirically compared fifteen popular deep learning optimizers
Choosing the optimizer is considered to be among the most crucial design decisions in deep learning, and it is not an easy one. The growing literature now lists hundreds of optimization methods. In the absence of clear theoretical guidance and conclusive empirical evidence, the decision is often made based on anecdotes. In this work, we aim to replace these anecdotes, if not with a conclusive ranking, then at least with evidence-backed heuristics. To do so, we perform an extensive, standardized benchmark of fifteen particularly popular deep learning optimizers while giving a concise overview of the wide range of possible choices. Analyzing more than 50,000 individual runs, we contribute the following three points: (i) Optimizer performance varies greatly across tasks. (ii) We observe that evaluating multiple optimizers with default parameters works approximately as well as tuning the hyperparameters of a single, fixed optimizer. (iii) While we cannot discern an optimization method clearly dominating across all tested tasks, we identify a significantly reduced subset of specific optimizers and parameter choices that generally lead to competitive results in our experiments: Adam remains a strong contender, with newer methods failing to significantly and consistently outperform it. Our open-sourced results are available as challenging and well-tuned baselines for more meaningful evaluations of novel optimization methods without requiring any further computational efforts.
@inproceedings{Schmidt2021CrowdedValley, author = {Schmidt, Robin M. and Schneider, Frank and Hennig, Philipp}, booktitle = {International Conference on Machine Learning (ICML)}, title = {{Descending through a Crowded Valley - Benchmarking Deep Learning Optimizers}}, year = {2021}, url = {https://proceedings.mlr.press/v139/schmidt21a.html}, }


2019
- DeepOBS: A Deep Learning Optimizer Benchmark SuiteFrank Schneider, Lukas Balles, and Philipp HennigIn International Conference on Learning Representations (ICLR), 2019We provide a software package that drastically simplifies, automates, and improves the evaluation of deep learning optimizers
Because the choice and tuning of the optimizer affects the speed, and ultimately the performance of deep learning, there is significant past and recent research in this area. Yet, perhaps surprisingly, there is no generally agreed-upon protocol for the quantitative and reproducible evaluation of optimization strategies for deep learning. We suggest routines and benchmarks for stochastic optimization, with special focus on the unique aspects of deep learning, such as stochasticity, tunability and generalization. As the primary contribution, we present DeepOBS, a Python package of deep learning optimization benchmarks. The package addresses key challenges in the quantitative assessment of stochastic optimizers, and automates most steps of benchmarking. The library includes a wide and extensible set of ready-to-use realistic optimization problems, such as training Residual Networks for image classification on ImageNet or character-level language prediction models, as well as popular classics like MNIST and CIFAR-10. The package also provides realistic baseline results for the most popular optimizers on these test problems, ensuring a fair comparison to the competition when benchmarking new optimizers, and without having to run costly experiments. It comes with output back-ends that directly produce LaTeX code for inclusion in academic publications. It is written in TensorFlow and available open source.
@inproceedings{Schneider2018DeepOBS, title = {Deep{OBS}: A Deep Learning Optimizer Benchmark Suite}, author = {Schneider, Frank and Balles, Lukas and Hennig, Philipp}, booktitle = {International Conference on Learning Representations (ICLR)}, year = {2019}, url = {https://openreview.net/forum?id=rJg6ssC5Y7}, }

2018
-
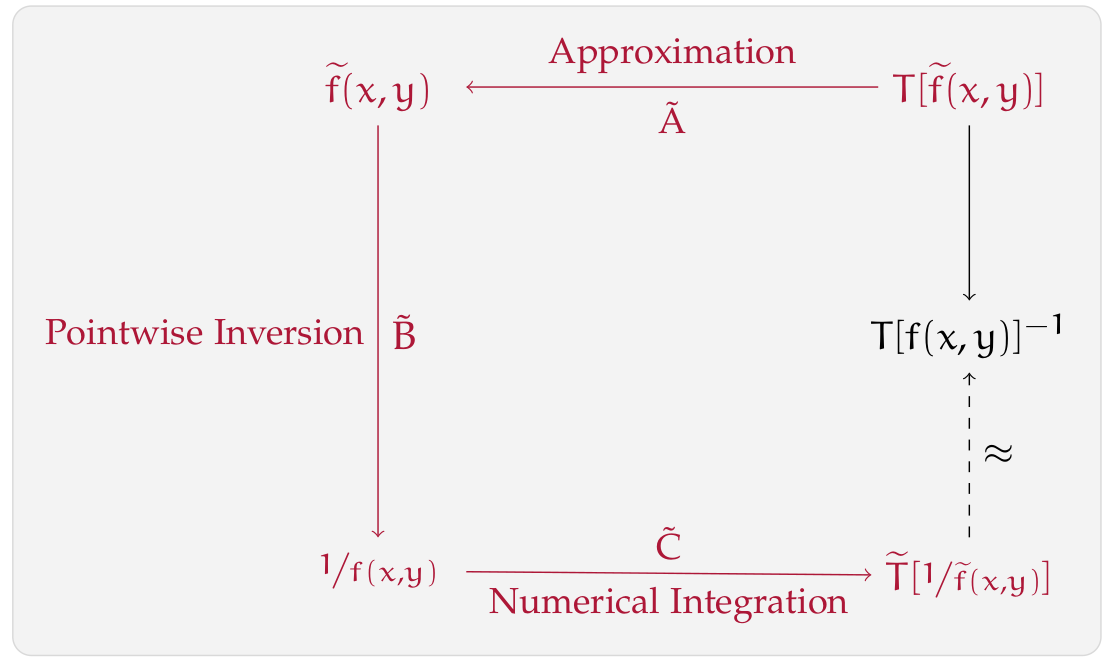 Inverse generating function approach for the preconditioning of Toeplitz-block systemsFrank Schneider, and Maxim PisarencoNumerical Linear Algebra with Applications, 2018We propose a new preconditioner for Toeplitz-block matrices based on the inverse generating function
Inverse generating function approach for the preconditioning of Toeplitz-block systemsFrank Schneider, and Maxim PisarencoNumerical Linear Algebra with Applications, 2018We propose a new preconditioner for Toeplitz-block matrices based on the inverse generating functionAs proposed by R. H. Chan and M. K. Ng (1993), linear systems of the form \(T[f]x=b\), where \(T[f]\)denotes the \(n \times n\)Toeplitz matrix generated by the function \(f\), can be solved using iterative solvers with \(T[\frac1f]\)as a preconditioner. This article aims at generalizing this approach to the case of Toeplitz-block matrices and matrix-valued generating functions \(F\). We prove that if \(F\)is Hermitian positive definite, most eigenvalues of the preconditioned matrix \(T[F^-1]T[F]\)are clustered around one. Numerical experiments demonstrate the performance of this preconditioner.
@article{Schneider2018IGF, title = {Inverse generating function approach for the preconditioning of Toeplitz-block systems}, author = {Schneider, Frank and Pisarenco, Maxim}, journal = {Numerical Linear Algebra with Applications}, volume = {25}, number = {5}, pages = {e2168}, year = {2018}, publisher = {Wiley Online Library}, doi = {10.1002/nla.2168} } -
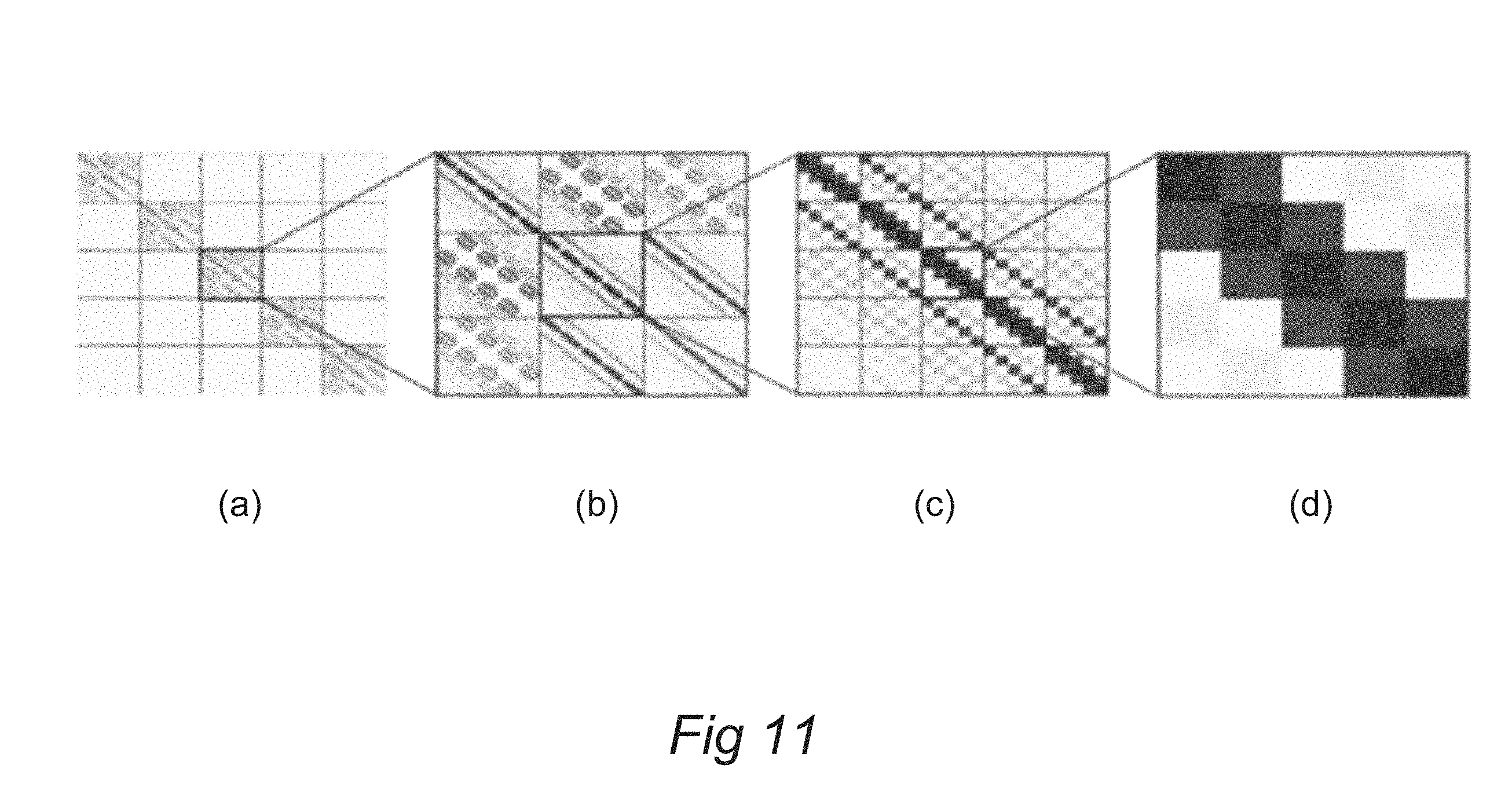 Methods and Apparatus for Calculating Electromagnetic Scattering Properties of a Structure and for Reconstruction of Approximate StructuresMaxim Pisarenco, Frank Schneider, Maria Van, and 2 more authors2018US Patent App. 15/839,299We propose two new preconditioners for multi-level Toeplitz matrices
Methods and Apparatus for Calculating Electromagnetic Scattering Properties of a Structure and for Reconstruction of Approximate StructuresMaxim Pisarenco, Frank Schneider, Maria Van, and 2 more authors2018US Patent App. 15/839,299We propose two new preconditioners for multi-level Toeplitz matricesDisclosed is a method for reconstructing a parameter of a lithographic process. The method comprises the step of designing a preconditioner suitable for an input system comprising the difference of a first matrix and a second matrix, the first matrix being arranged to have a multi-level structure of at least three levels whereby at least two of said levels comprise a Toeplitz structure. One such preconditioner is a block-diagonal matrix comprising a BTTB structure generated from a matrix-valued inverse generating function. A second such preconditioner is determined from an approximate decomposition of said first matrix into one or more Kronecker products.
@misc{Pisarenco2018Methods, title = {Methods and Apparatus for Calculating Electromagnetic Scattering Properties of a Structure and for Reconstruction of Approximate Structures}, author = {Pisarenco, Maxim and Schneider, Frank and Van, Maria and Martinus, Kraaij Markus Gerardus and Van Beurden, Martijn Constant}, year = {2018}, note = {US Patent App. 15/839,299}, }


2016
-
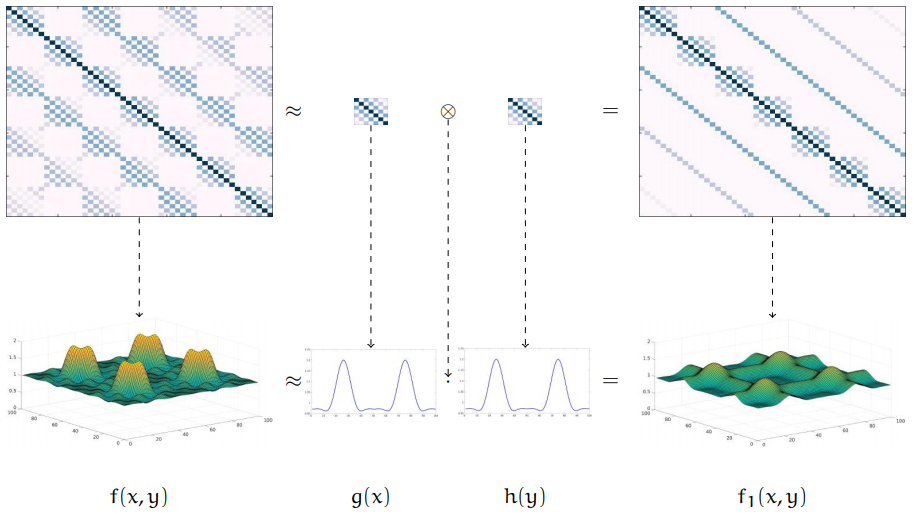 Approximations of Inverses of BTTB MatricesFrank SchneiderTechnische Universiteit Eindhoven (TU/e), 2016Master’s ThesisWe suggest several techniques to approximate the inverse of a BTTB matrix with the goal of designing preconditioners for linear systems of this form.
Approximations of Inverses of BTTB MatricesFrank SchneiderTechnische Universiteit Eindhoven (TU/e), 2016Master’s ThesisWe suggest several techniques to approximate the inverse of a BTTB matrix with the goal of designing preconditioners for linear systems of this form.The metrology of integrated circuits (ICs) requires multiple solutions of a large-scale linear system. The time needed for solving this system, greatly determines the number of chips that can be processed per time unit. Since the coefficient matrix is partly composed of block-Toeplitz-Toeplitz-block (BTTB) matrices, approximations of its inverse are interesting candidates for a preconditioner. In this work, different approximation techniques such as an approximation by sums of Kronecker products or an approximation by inverting the corresponding generating function are examined and where necessary generalized for BTTB and BTTB-block matrices. The computational complexity of each approach is assessed and their utilization as a preconditioner evaluated. The performance of the discussed preconditioners is investigated for a number of test cases stemming from real life applications.
@mastersthesis{Schneider2016BTTB, author = {Schneider, Frank}, title = {Approximations of Inverses of BTTB Matrices}, school = {Technische Universiteit Eindhoven (TU/e)}, year = {2016}, note = {Master's Thesis}, }
